RainbowCake
A modern Android architecture framework
Introduction
This is the documentation of the RainbowCake architecture concept for Android applications. RainbowCake relies heavily on Kotlin languages features and the Google Jetpack libraries.
Note: RainbowCake is stable and maintained, but it’s a framework from 2019, so browse and use it with that in mind. You’ll find a lot of the same ideas in Google’s official Guide to app architecture as well, which is updated more actively.
Just like Jetpack - which it essentially extends - RainbowCake is both a set of dependencies that contain classes and other constructs to use in your applications, and guidance on how these applications should be implemented.
The main goals of this architecture:
- Clearly separate concerns between different layers and components,
- Always keep views in a safe and consistent state with ViewModels,
- Handle configuration changes (and even process death) gracefully,
- Make offloading work to background threads trivial.
Overview
A brief description of the architecture’s layers, for a start:
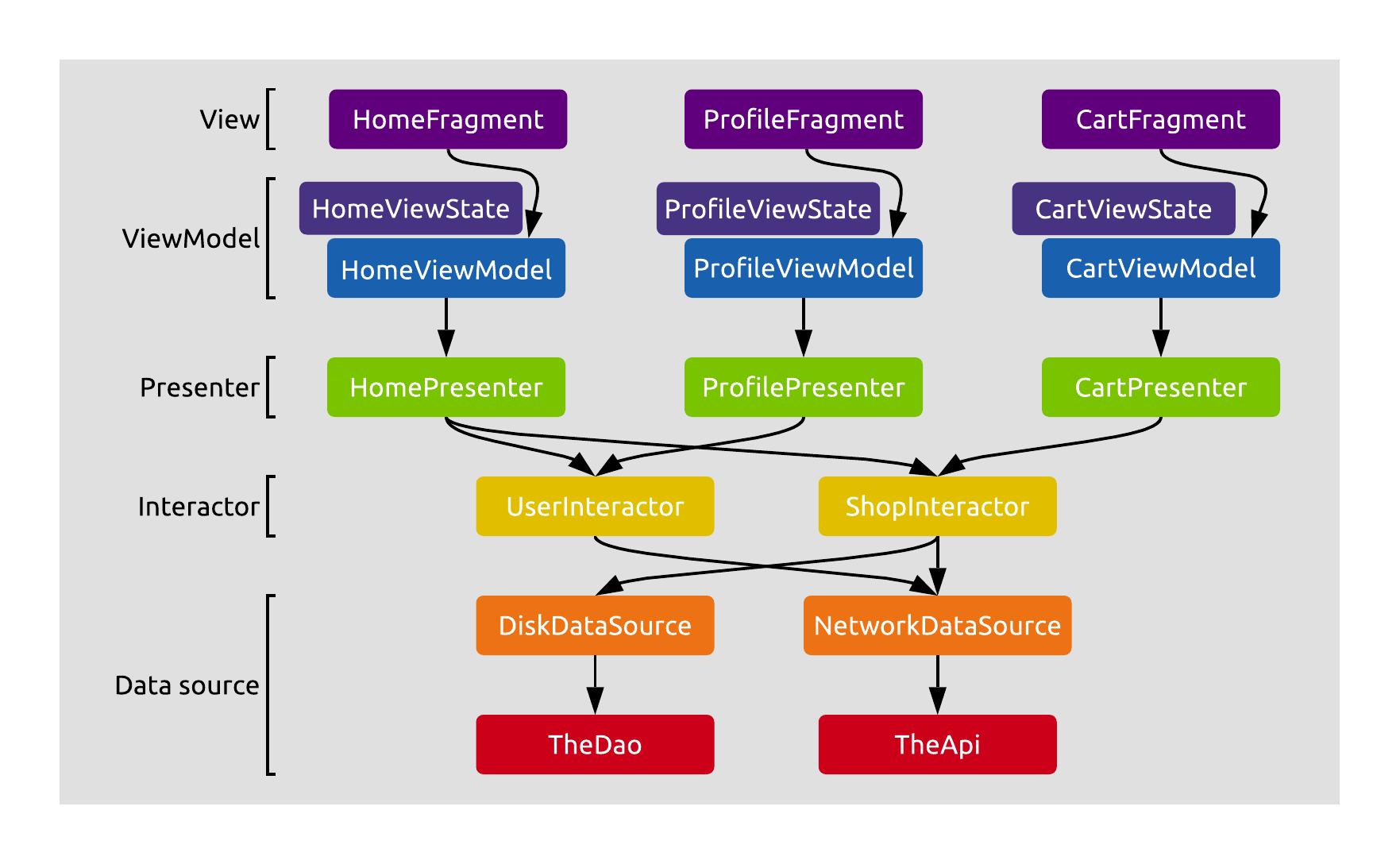
- Views (Fragments or Activities) represent application screens. They observe immutable state from their respective ViewModels and display it on the UI. They also forward input events to the ViewModel, and may receive state updates or one-time events in return.
- ViewModels store the current state of the UI, handle UI related logic, and update the state based on results received from presenters. They start coroutines for every task they have to perform (triggered by input events), and forward calls to their presenters.
- Presenters put work on background threads and use interactors (one or more) to access business logic. Then, they transform the results to screen-specific presentation models for the ViewModels to store as state.
- Interactors contain the core business logic of the application. They aggregate and manipulate data and perform computations. They are not tied to a single screen, but instead group functionality by the major features of the application.
- Data sources provide the interactors with data from various origins - local database and file system, network locations, key-value stores, system APIs, resources, etc. It’s their responsibility to abstract away the underlying implementation from the domain layer, and to keep their stored data in a consistent state (i.e. not expose operations that can lead to inconsistency).
A grain of salt
This architecture concept and this documentation isn’t gospel. What’s being described here is the full capabilities of the architecture and some design recommendations that are known to work well with it. If your specific application’s needs require you to deviate from this, please do - this is encouraged. Read more here.